Modelos de atribución en marketing. Markov (5/6)
En esta serie de notas vamos a ver qué son y cómo se usan en marketing los modelos de atribución. La pregunta que buscamos responder es: de las ventas que tuvimos, ¿cuántas corresponden a cada campaña publicitaria que hicimos? Para eso analizamos las 2 familias principales de modelos: MMM (Marketing Mix Modelling) y MTA (Multi Touch Attribution).
Índice
- ¿Qué es la atribución?
- Modelos MMM
- Modelos MTA: heurísticos
- Modelos MTA: data-driven (Shapley)
- Modelos MTA: data-driven (Markov)
- Resumen
Markov
El segundo enfoque de esta serie es el de Markov. Como pasa muchas veces con ciertos términos, se convierten en “buzzwords” o, dicho en criollo, palabras que usás para inflar de ceros un presupuesto.
A diferencia de Shapley, donde la relación entre el término y la aplicación es bastante directa (se usa el cálculo de Lord Shapley para determinar cuánto se lleva cada canal), en este caso la relación es más difícil de establecer. Markov en realidad fue un matemático ruso que en 1906 escribió sobre procesos en los que la ocurrencia de un evento solamente depende del estado inmediatamente anterior. También fue un jugador de hockey sobre hielo ruso-canadiense. Adiviná cuál es cuál…

¿Qué tiene que ver esto con la atribución de la que veníamos hablando? Eso vamos a descifrar, acompañame.
Teoría de la probabilidad
Así como el modelo de Shapley hunde sus raíces en la teoría de juegos, el de Markov hace lo mismo con la teoría de la probabilidad. Esta es una vertiente de la matemática donde se estudian procesos aleatorios, es decir fenómenos que dependen del azar o de variables que no se pueden determinar a priori. Como te podrás imaginar, en este tipo de problemas es muy importante saber la probabilidad de ocurrencia de un evento, de ahí el nombre ;).
Markov hizo muchos aportes a este campo pero vamos a quedarnos con algo muy simple que es lo que nos va a servir para esta nota, lo que llamamos “cadenas de Markov”. Básicamente el planteo arranca con que la probabilidad de ocurrencia de un evento solo depende del estado anterior de la variable. Es decir, es una teoría que se usa para modelar variables “sin memoria”, que no les importa lo que haya sucedido en el pasado, solo lo inmediatamente anterior.
Vamos a verlo con un gráfico, te juro que es fácil:
Supongamos que A es un día soleado y B es un día de lluvia. Las flechas representan la probabilidad de pasar de un estado al otro o de permanecer en el mismo. Tomando este ejemplo, la probabilidad de que llueva dado que el día anterior estuvo soleado, es de 20%. Y una vez que arranca a llover, agarrate, porque la probabilidad de que al día siguiente siga lloviendo es 80%. Con solo ver esto, nos podemos imaginar que el clima en este lugar del mal está compuesto por muchos días soleados seguidos cada tanto de una racha de días de lluvia.
En este caso, lo que hicimos al modelar el clima con cadenas de Markov fue partir de que la probabilidad de un día de ser soleado o lluvioso solo depende de lo sucedido el día anterior, es decir de cuál es el estado previo de esa variable de “clima”.
Markov en marketing
Ahora bien… ¿para qué nos puede servir esto en el marketing?
En el caso de los datos de clima, parece bastante clara la aplicación. Sin embargo, los datos que veníamos usando en las notas anteriores también pueden ser modelados siguiendo esta metodología. Tomemos el ejemplo que usamos para Shapley:

Usando estas interacciones, podemos construir un grafo (el dibujo ese con flechas) para representar los datos como una cadena de Markov. Sería algo así:
Simplemente dibujamos un nodo (circulito) con cada canal y trazamos las aristas (flechitas) con la cantidad de ocurrencias de cada una. Para completar el grafo, nos faltan 2 pasos.
El primero es agregar el estado inicial y los estados finales. El estado inicial sirve simplemente para explicitar cuál es la probabilidad de que el recorrido arranque por uno u otro canal. En este caso, vemos que hay 2 que empiezan en orgánico y 1 en youtube pero agregando el estado inicial eso se ve más claro. ¿Qué es el estado inicial? Simplemente otro nodo (circulito) que se llama “inicio” (como en el juego de la oca).
En cambio el estado final, que en nuestro caso sería conversión o no conversión nos lleva a un tipo de cadena de Markov particular que son las cadenas con estados absorbentes. ¿Qué quiere decir esto? Que básicamente toda iteración o proceso termina con uno de estos estados. Es decir, todo recorrido termina sí o sí en conversión o en no conversión. O dicho de otra manera, una vez que el usuario llega a la conversión (o a la no conversión), ahí termina su recorrido.
Si los estados absorbentes te hicieron un poco de ruido, está bien. Más adelante vamos a desarrollar las intuiciones (o contra intuiciones) de este planteo así cómo las consecuencias matemáticas de modelar de esta manera.
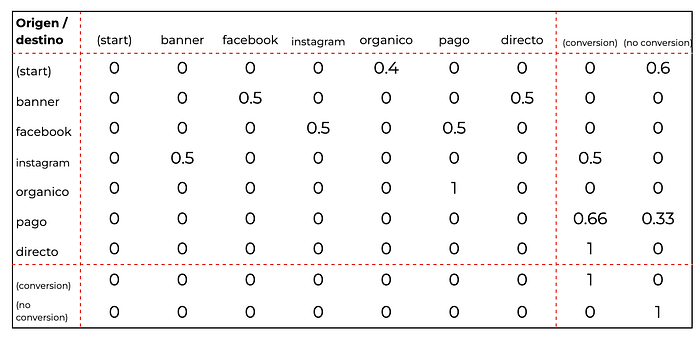
El último paso es cambiar los valores de las aristas. En vez de poner valores absolutos, vamos a pasarlos a probabilidades dividiendo el valor de cada salida por la cantidad de salidas totales de cada nodo. Mejor que decir es hacer, acá va:
Este sería el grafo final. Es una manera muy gráfica de representar la relación entre los canales en los recorridos de los usuarios. Hay otra manera de representar esta misma información y es a partir de lo que llamaremos una matriz de transición. Básicamente es la misma información pero en una tabla. Las filas representan el canal de origen y las columnas, el canal de destino. Para este caso, sería así:
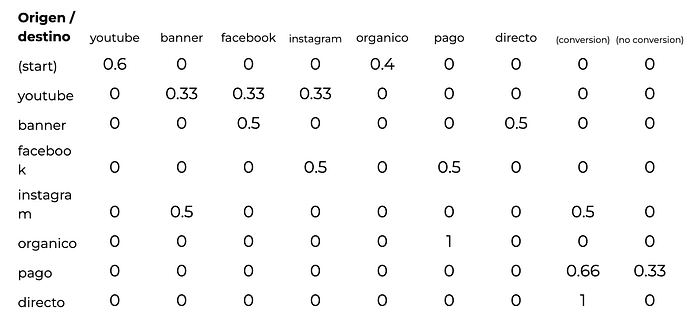
La tasa de conversión
Supongamos que hasta acá está todo bien. Los caminos por los que transcurren los usuarios nos hablan de ciertas probabilidades relativamente estables de pasar de uno a otro y de llegar (o no) a la conversión. Ahora, ¿cómo podemos usar esta información?
Usualmente cuando se modelan cadenas de Markov, la matriz de transición nos sirve para calcular la probabilidad de ir desde un punto a otro. Supongamos que queremos saber cuán probable es llegar desde start hasta conversión. ¿Qué resultado debería darnos? PENSALO.
Si dijiste tasa de conversión, palmadita en la espalda. Sino, no pasa nada, la idea es ver si podemos calcularlo a partir de Markov.
Tomando este grafo, tenemos 3 caminos para llegar a la conversión: desde directo, instagram y pago. Pero a su vez, tenemos varias formas de llegar a cada uno de esos canales.
Arrancamos por la primera rama. Si de start llegamos a youtube, podemos ir a banner, directo y conversión; a instagram y conversión; a instagram, banner, directo y conversión; o a facebook que nos abre muchas otras posibilidades. La segunda rama es más fácil, de orgánico vamos a pago y a conversión, corta la bocha.
Ahora pongamos número a estas opciones. Cada uno de esos caminos tiene una probabilidad distinta de ocurrencia. El nombre técnico de lo que estamos haciendo es el cálculo de la probabilidad conjunta pero se puede hacer desde el grafo muy visualmente.
Así sería técnico:
P (start > youtube > banner > directo > conversion) =
P (youtube / start) * P (banner / youtube) * P (directo / banner) * P (conversion / directo)
P (start > youtube > banner > directo > conversion) =
0.6 * 0.33 * 0.5 * 1 = 0,1
Así sería visual:
Si repetimos este mismo proceso para todos los posibles caminos que llevan a la conversión y sumamos sus probabilidades, nos da aproximadamente 0,8. “Aproximadamente” es porque hay caminos infinitos (ya que podríamos caer en un cuento de la buena pipa con youtube > instagram > banner > facebook > instagram > banner > facebook > …) pero sin embargo los resultados se aproximan a 0,8. Y 0,8 si nos fijamos es justamente la tasa de conversión que teníamos al principio: de 5 recorridos, hay 4 que convierten. ¡Bien! (auto palmadita).
Este es el momento en que decís… ¿y entonces para qué hicimos todo esto? Los grafos, los cálculos, ¿todo para llegar al mismo resultado que si contábamos al principio cuántos convertían y cuántos no? Bueno, acá es cuando la magia happens.
La manera en la que agarramos recién el camino de youtube > banner > directo > conversión y calculamos su probabilidad es un poco rústica. Sin embargo, y acá le damos las gracias a Andrei (Markov, por si lo habías olvidado), existe una fórmula matemática para reemplazar esas cuentas.
Como la cadena de Markov es absorbente (acordate que esto era que tenían estados en los que todo recorrido terminaba necesariamente), la matriz de transición en realidad está compuesta por 4 elementos que vamos a llamar de la siguiente manera:
- Q: transición entre estados no absorbentes o transición entre canales.
- R: transición entre no absorbentes y absorbentes, es decir probabilidad de cada canal de ser last click (acá te metí un crossover con los modelos heurísticos de hace varias temporadas, si no lo seguiste no importa).
- 0: una matriz de ceros que son todas las transiciones de absorbentes (conversión o no conversión) a no absorbentes (canales). Dicho fácil, de los estados conversión o no conversión no vas a ningún lado así que 0.
- I: la matriz diagonal de los estados absorbentes. Es decir cuando llegaste a conversión o no conversión te quedás ahí con 100% de probabilidad.
NO ENTIENDO.
Bueno, miralo acá:
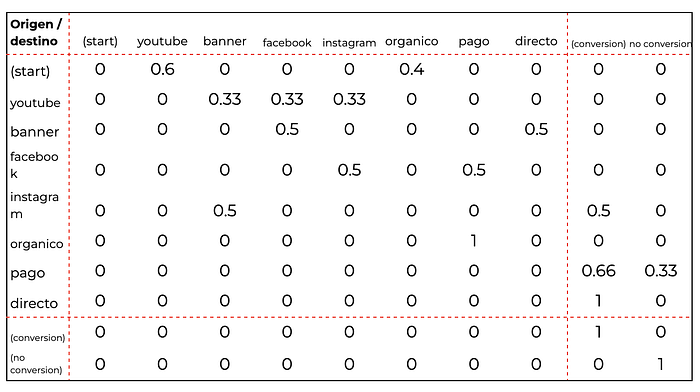
O más claro todavía:

Y ta tan ta tan, una vez que tenemos esto solo nos queda resolver la matriz (multiplicar R por la inversa de I-Q; matemática, no lo entenderías) y obtenemos algo con un nombre muy pomposo que es “la matriz estable de transición”. Que básicamente nos va a indicar qué probabilidad hay de terminar en cada uno de los estados absorbentes partiendo de cualquiera de los estados no absorbentes.
Podés hacer las cuentas pero si elegís creerme, estos son los resultados:
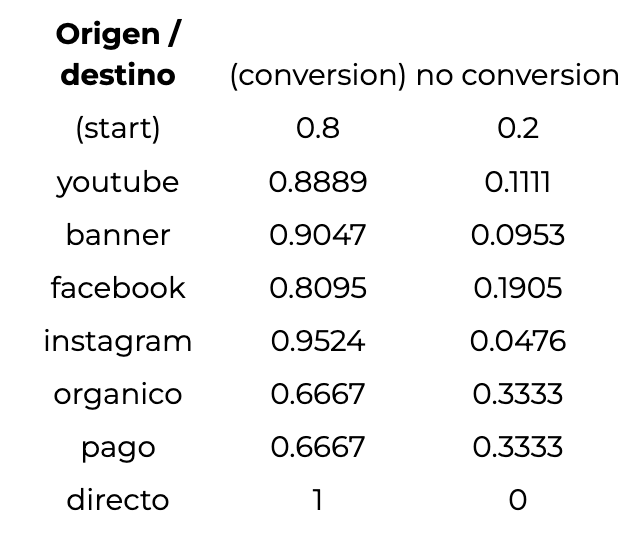
Esto nos dice partiendo de cada canal, qué probabilidades tenemos de terminar en conversión o en no conversión. Si miramos la primera línea, la de start, una vez más llegamos al mismo resultado original: 80% de probabilidad de terminar en conversión. Sin embargo, lo bueno de esto es que llegamos al mismo resultado pero esta vez de una manera muy sencilla (tablita y un poco de matemática), que podemos replicar para cualquier conjunto de datos.
Repasemos el proceso: tenemos datos de usuarios, armamos los caminos que cada usuario siguió y si llevaron a una conversión o no, calculamos la probabilidad de pasar de uno a otro para todos los canales, pasamos eso a una tabla, hacemos estas cuentas mágicas y pum, tenemos los resultados.
Sigue flotando en el aire la pregunta… ¿PARA QUÉ? Esta primera temporada fue de presentación de los personajes, ahora viene la segunda temporada y todo explota.
Efecto remoción
Volvamos un poco al punto de partida. Queremos saber qué atribución tiene cada canal. Es decir, qué responsabilidad tiene cada canal en las conversiones totales. Una manera intuitiva de hacer eso sería preguntarse “¿qué pasaría si este canal no existiera?”. Al comparar el escenario en el que el canal no existe contra el escenario en el que sí, podríamos tener una noción de cuánto “aporta” ese canal a las conversiones. ¿No?
Bueno, el problema es que el canal existe, entonces no tenemos manera de simular ese escenario donde el canal no existe.
No teníamos. Ahora que tenemos Markov, sí podemos hacerlo. Fijate que es tan simple como borrar una fila y una columna de la tabla y listo, desaparece el canal y podemos recalcular la tasa de conversión.
Pensalo un minuto. Tiene sentido, ¿no?
Esto que te acabo de contar no es algo que se le haya ocurrido a Markov ni que estuviera planteado en su teoría sino que es una aplicación que se utilizó por primera vez en papers de los años 2005 y 2006. A este truquito basado en las cadenas de Markov se lo llama efecto remoción porque es justamente el cálculo de la diferencia en la tasa de conversión al quitar o remover un canal. Ahora bien, acá es donde entran los detalles técnicos.
Sres. Detalles Técnicos
Normalizar los valores (o la cuentita para llegar al resultado)
El primer detalle técnico es que si calculamos el efecto remoción de una manera bastante tradicional sería algo así como
(tasa_de_conversión_original — tasa_de_conversión_sin_canal) / (tasa_de_conversion_original)
Esto nos daría un porcentaje de reducción de la tasa de conversión. Cool, ¿no? Ahora bien… ¿cómo pasamos de eso a una atribución para un canal?
Bueno, ahí viene el truquito para este detalle técnico que consiste en normalizar esos efectos remoción de cada canal para que entre todos sumen 1 y de esa manera sabemos qué porcentaje de toda la disminución posible (hipotética) se lleva cada canal.
Es decir, sumamos todos los efectos remoción y después dividimos cada uno por ese total. Eso nos va a dar un porcentaje que después aplicamos a las conversiones totales para saber a cuántas conversiones equivale la parte de cada canal.
Remoción al estado nulo (o qué hacemos con lo que borramos)
Ponele que hasta acá me creés y suena todo bastante coherente. Acá viene el detalle técnico número 2. La pregunta sería… cuando removemos un canal, eliminamos la fila y la columna… pero ¿qué pasa con la gente que iba a llegar a ese canal en su recorrido?
Volvamos al grafo original
Supongamos que estamos calculando el efecto remoción para el canal youtube… ¿qué pasa con esas 3 personas que iban a parar a YouTube? ¿Asumimos que siguen su camino como si YouTube no estuviera? ¿O sea mandamos 1 a banner, 1 a instagram y 1 a facebook? Tiene sentido.
Sin embargo, cuando calculamos el efecto remoción para directo, ¿qué hacemos? Porque con ese mismo criterio tendríamos que decir que la persona que llegó ahí en realidad iría a conversión, con lo cual la tasa de conversión sería la misma sin ese canal o sea que su atribución debería ser 0. ¿Y si analizamos orgánico? Pasa lo mismo, el 100% de los usuarios pasarían a pago y se obtendría la misma tasa de conversión por lo que el efecto remoción sería 0. Sería un modelo de atribución bastante injusto, ¿no?
Bueno, la solución de la gente que propuso esta metodología por primera vez en un paper fue que al calcular el efecto remoción, los usuarios que llegaban a ese canal pasen directamente al estado nulo o de no conversión. Es decir, si no pasan por el canal, se termina su recorrido. Suena bastante drástico, pero es la manera más equilibrada de resolverlo.
La interpretación es que ese canal es el que vuelve a traer al usuario al sitio. Asumimos que sin ese canal, el usuario no entra más (o por lo menos en el período bajo análisis). De vuelta: suena drástico pero tiene sentido cuando queremos analizar acciones de marketing que se supone que tienen una influencia en los usuarios y no que son simplemente pasos dentro de un recorrido.
Vamos a poner 2 ejemplos como para que se entienda la parte de las cuentas:
- Efecto remoción de youtube
Para calcularlo, eliminamos la fila correspondiente a youtube (chau youtube) pero también la columna. Pero antes de eliminar la columna, buscamos las filas donde hay valores distintos de 0 y los reasignamos a la columna de no conversión.
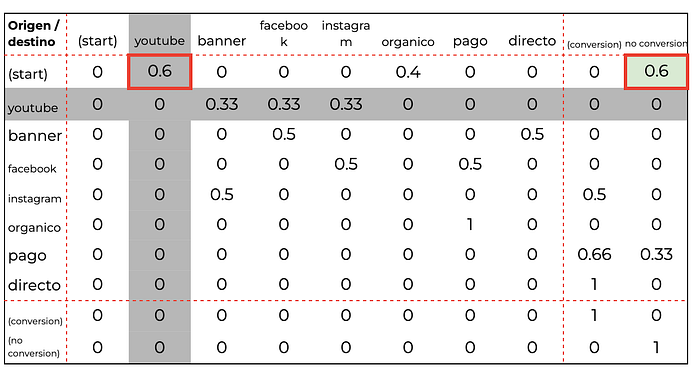
Una vez hecho esto, volvemos a hacer las cuentas sobre la matriz sin youtube (chau youtube).
Si resolvemos esta matriz como aprendimos hace un rato, el resultado es que la probabilidad de conversión es 26,67%. Ahora vamos a aplicar la formulita del detalle técnico 1. Recordamos:
(tasa_de_conversión_original — tasa_de_conversión_sin_canal) / (tasa_de_conversion_original)
O sea que el efecto remoción de youtube es (aprox):
(0,8889–0,2667) / (0,8889) = 70%
O sea, bastante. Vamos a ver qué pasa con orgánico
- Efecto remoción de orgánico
Primero achuramos la tabla (si esto fuera una clase, te la hubiera dado de tarea).

Después calculamos la matriz estable de transición y nos da que la probabilidad de conversión partiendo de start es 46,67%. Esta vez el efecto remoción es 47,5%. Un poco menos que youtube.
Por si te daba curiosidad, acá te dejo cómo quedarían los efectos remoción de cada canal, después de normalizar y multiplicando ese porcentaje por la cantidad total de conversiones (en este caso, 4).
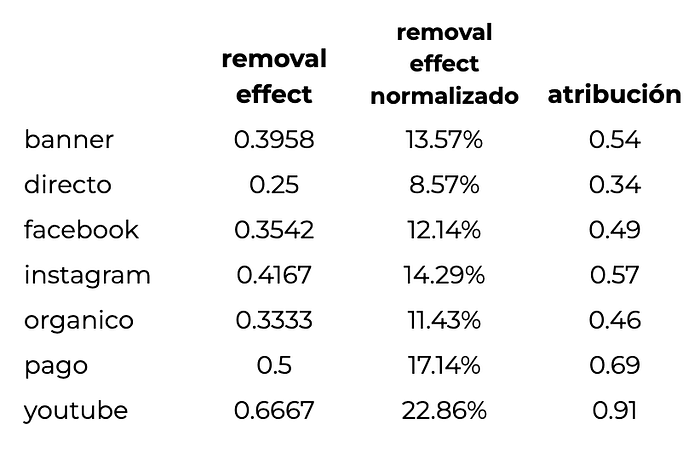
¿Qué te parece?
Independencia de la matriz respecto a los recorridos
El tercer detalle técnico es el siguiente: hasta ahora pasábamos de recorridos a matriz de transición. Pero ¿qué pasa si lo pensamos a la inversa? Una determinada matriz de transición no está necesariamente asociada a una sola combinación de recorridos de usuarios.
Sigamos con nuestro ejemplo.
Esta matriz de transición estaba asociada a estos recorridos de usuarios.
Y si en lugar de esos recorridos, ¿tuviéramos estos?

¡Sorpresa! La matriz de transición sería la misma. Esto quiere decir que la atribución en ambos casos sería idéntica. Veamos por ejemplo el caso del canal pago. En ambos casos forma parte de 2 caminos de conversión y uno de no conversión. Sin embargo, en el segundo ejemplo, uno de esos caminos de conversión (el del usuario 5) es bastante más largo que su homónimo en el primer ejemplo (el usuario 4). La atribución de pago en un camino más chico debería ser (imaginamos, sentido común) un poco menor que en un camino más largo. Sin embargo, acá no lo es ya que el resultado de la misma matriz de transición es exactamente la misma atribución. ¿Por qué?
Bueno, justamente por la característica que planteamos al principio cuando enunciamos los modelos de Markov. Están basados solamente en lo que sucede en el estado inmediatamente anterior. Es decir que en Markov se pierde la noción de caminos de usuarios para ser reemplazada por transiciones entre canales. Los canales ya no forman parte de un recorrido sino que vienen de a pares, de uno se pasa al otro y eso es todo lo que importa.
Agregando órdenes
Si este supuesto de que los recorridos no tengan memoria no te está cerrando mucho, me alegro que hayas llegado hasta acá. Como siempre que modelamos, primero montamos unos supuestos sobre la realidad y después intentamos flexibilizarlos para poder adaptarnos a otros escenarios. Es exactamente lo que vamos a hacer ahora.
Para flexibilizar el supuesto de que nada de lo que pasa importa salvo el último estado, existen los modelos de Markov de órdenes superiores. Es decir, lo que vimos hasta ahora son cadenas de Markov de orden 1. Un modelo de Markov de orden 2, por ejemplo, es un modelo donde además de tener en cuenta el último estado de la variable, también tenemos en cuenta el anterior a ese. Es decir, ahora se alarga un poquito más la “memoria” del modelo.
A su vez, estos modelos tienen una propiedad que nos va a hacer la vida mucho más fácil: resolver un modelo de orden 2 es lo mismo que resolver un modelo de orden 1 pero para pares de canales. Veámoslo con el ejemplo:
Estos eran los recorridos. A partir de los mismos habíamos construido esta matriz de transición para representar el modelo de orden 1, agregando el estado inicial (start) y los estados absorbentes (conversión) y (no conversión).
Ahora si queremos construir un modelo de orden 2 lo que vamos a hacer es reemplazar a los canales por pares de canales. Nuevamente, es más fácil hacerlo que decirlo.
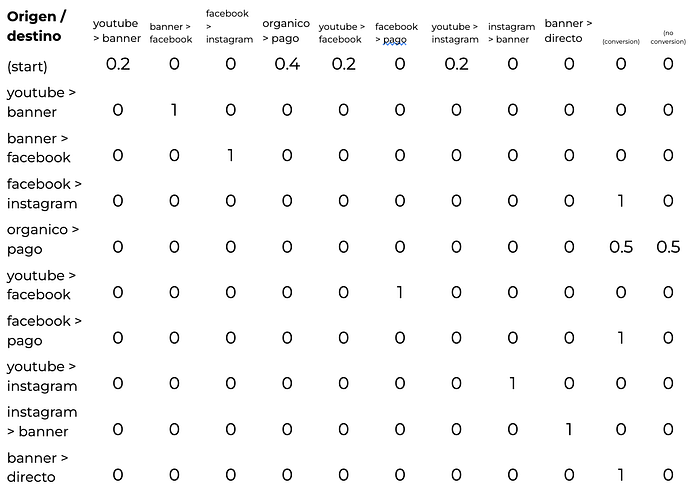
A partir de aquí podemos continuar como lo habíamos hecho antes con un pequeño detalle. ¿Qué obtenemos cuando resolvemos la matriz?
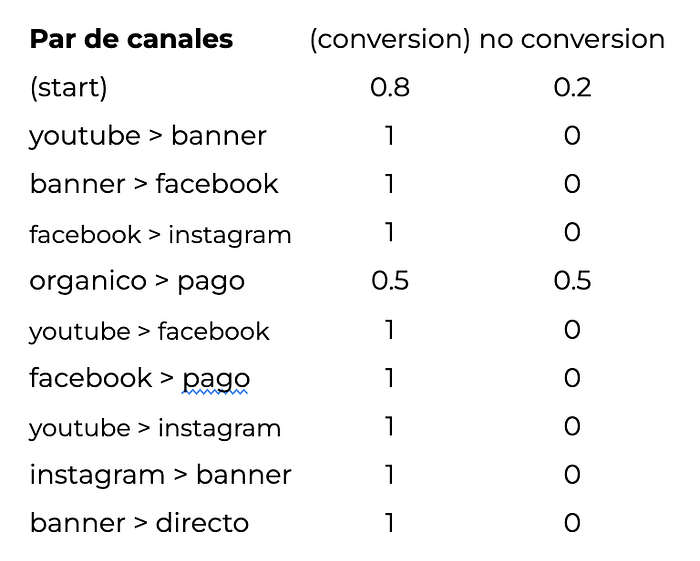
Primero chequeamos que la probabilidad de conversión partiendo de (start) nos sigue dando 0.8, punto para nuestro cálculo. Ahora sí, seguimos la misma metodología de antes: vamos quitando de a un canal (par de canales en este caso) por vez y recalculamos la tasa de conversión, anotando para cada canal (par de canales) cuál es la variación entre la tasa de conversión original y la calculada sin ese canal.
El resultado final es el siguiente:
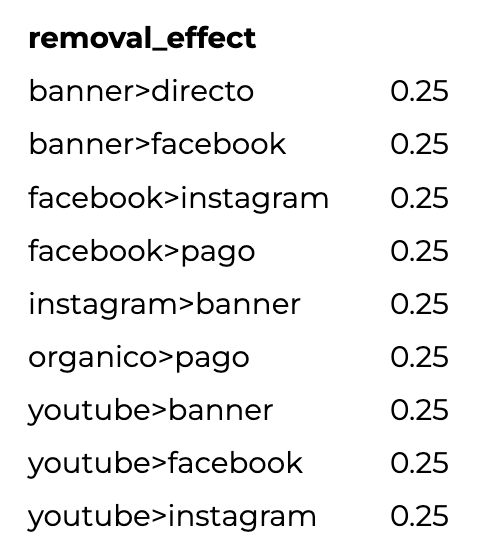
No hace falta normalizar para darnos cuenta que las 4 conversiones se van a repartir equitativamente entre todos los canales (pares de canales). Parece medio una estafa pero aguantame porque falta un paso más.
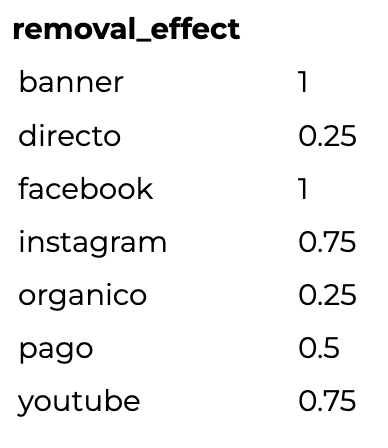
Para obtener la atribución de cada canal, tenemos que dar un paso más ya que este resultado está puesto en función de pares de canales. ¿Entonces qué hacemos? ¿Cómo dividimos esa atribución entre los 2 canales que forman el par?
El cálculo más sencillo es sumar para cada canal el removal effect de todas las combinaciones donde aparece. Luego de eso, normalizar los valores para obtener el porcentaje. En este caso, sería así:
Y una vez que normalizamos y aplicamos las 4 conversiones, el resultado es:
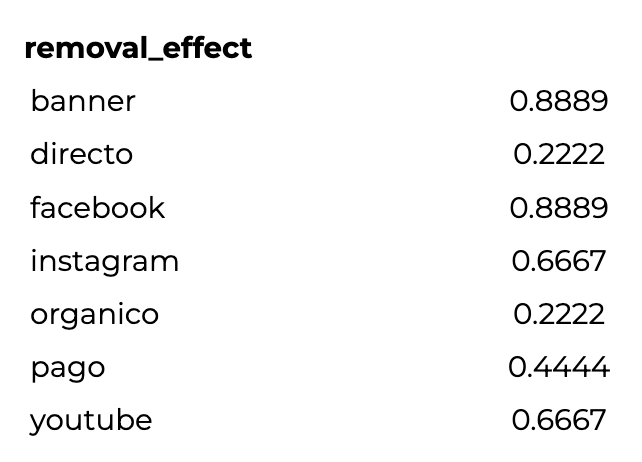
Una vez que obtuvimos este resultado, podemos comparar cómo es la atribución entre el modelo de orden 1 y el de orden 2.

Al ser un ejemplo de juguete, no podemos sacar muchas conclusiones sobre este análisis pero sí nos sirve para ver cómo varía la atribución entre uno y otro.
Qué orden es el ideal
¿Por qué hablamos de “agregar órdenes”? Porque en este caso pusimos un ejemplo para un modelo de Markov de orden 2 pero podríamos aplicar el mismo razonamiento para orden 3, orden 4, etcétera. ¿Qué problemas extras se nos agregan a medida que vamos sumando órdenes?
Por un lado, al pasar de orden 1 a orden 2, en vez de los 7 canales originales pasamos a tener 9 pares de canales (podrían ser más incluso). Esto hace que la matriz sea más dispersa, es decir que haya más 0 al armar las transiciones entre los canales porque cada combinación de par de canales está menos presente en los datos. Cuando esto pasa, el resultado final del modelo es más volátil o menos representativo.
Por otro lado, al agregar órdenes mayores, hay recorridos de usuarios que pueden quedarnos afuera. Por ejemplo, en el caso que acabamos de ver todos los recorridos de los usuarios están presentes porque todos tienen 2 o más canales. Si algún recorrido tuviera 1 solo canal, no podría entrar en el cálculo del modelo de Markov de orden 2. Por lo tanto, si nos vamos a un orden alto tenemos que tener en cuenta que podemos estar perdiendo muchos recorridos en el medio y que el resultado final sea menos representativo.
Resumiendo
Markov es una forma de representar los caminos de los usuarios como transiciones entre canales. Esto nos permite aprovechar el herramental matemático de resolución de matrices con estados absorbentes (fua, qué nombre) para calcular hipotéticamente cuál sería la probabilidad o tasa de conversión si un canal no existiera y todos los usuarios de ese canal automáticamente pasaran a no convertir. Esto lo calculamos con el efecto remoción, que normalizando entre todos los canales y aplicándolo a la cantidad de conversiones totales nos dice cuánto es lo que debemos atribuir a cada uno. Además, utilizando modelos de Markov de mayor orden podemos flexibilizar el supuesto más exigente que es el de que una transición entre canales solo depende del estado inmediatamente anterior.
