Modelos de atribución en marketing. Modelos MTA (3/6)
En esta serie de notas vamos a ver qué son y cómo se usan en marketing los modelos de atribución. La pregunta que buscamos responder es: de las ventas que tuvimos, ¿cuántas corresponden a cada campaña publicitaria que hicimos? Para eso analizamos las 2 familias principales de modelos: MMM (Marketing Mix Modelling) y MTA (Multi Touch Attribution).
Índice
- ¿Qué es la atribución?
- Modelos MMM
- Modelos MTA: heurísticos
- Modelos MTA: data-driven (Shapley)
- Modelos MTA: data-driven (Markov)
- Resumen
Segunda respuesta: MTA
A medida que la publicidad digital empieza a ganar terreno desplazando a las formas más tradicionales, aparece una nueva oportunidad. Ahora es posible identificar personalmente (o algo parecido a eso) a quienes vieron una determinada publicidad. Esto nos permite reconstruir la historia de cada usuario: ¿que vio primero? ¿Qué vio después? ¿Después de qué publicidad compró?
Ahora la gran bolsa de información que teníamos agregada empieza a tener detalles propios del recorrido de cada usuario. Básicamente, puedo saber exactamente de dónde proviene un usuario que está comprando un producto en mi sitio web.
Siguiendo con los ejemplos sobre simplificados, este sería el tipo de información que podemos obtener, con todos los canales publicitarios por los que pasó un usuario antes de efectuar una compra. Para este análisis nos importan solo los usuarios que compraron así que vamos a excluir al usuario 3 del análisis.

Modelos heurísticos
Los primeros modelos que se desarrollan son los modelos heurísticos. Es decir, modelos que definen una regla más o menos arbitraria pero también clara sobre cómo atribuir cada conversión a un canal en particular.
Los dos modelos más extremos son el first-click y el last-click. En el primero, se le atribuye el 100% de la conversión al primer canal por el que ingresó un usuario (dado que sin ese canal no se lo hubiera “adquirido”) mientras que el otro le da el 100% de la conversión al último canal (por ser el que generó la compra).

No necesariamente hace falta posicionarse en un lado de la grieta y defender a muerte algunas de estas versiones (a menos que tu trabajo dependa de que valoren las campañas que se están haciendo en YouTubre) sino que son modelos que representan cosas distintas.
En el first-click se premia la adquisición de nuevos usuarios (y por ende las campañas de instalación de marca) y en el last-click se premia la efectividad para que usuarios que ya conocían la marca, compren (por eso premia a las campañas con descuentos o promociones).
Estos distintos objetivos de las campañas publicitarias tienen muchísimos nombres distintos pero que se pueden resumir bajo la idea de que primero das a conocer tu marca, luego ofrecés un producto determinado y finalmente generás el incentivo necesario para ejecutar la compra. Campañas lower y upper funnel, campañas de branding y de performance, de Know / Think / Do y un largo etcétera.
Otros modelos heurísticos tratan de equilibrar un poco entre estos dos extremos. Ejemplos de ello son: el modelo linear (que le da una importancia equivalente a todos los canales por los que atraviesa el usuario); el position based (que asigna el 80% entre el primer y el último canal y reparte el otro 20% entre el resto de los canales); o el time decay (que premia más al último y va decayendo en importancia a medida que nos alejamos de la conversión).
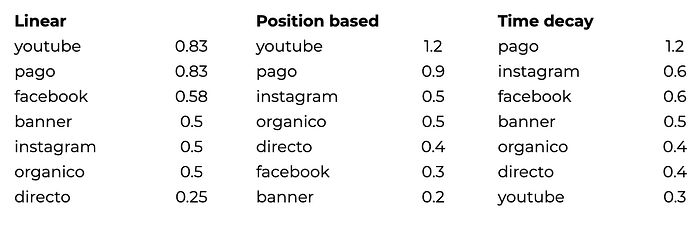
Podemos ver cómo cambian los resultados. No solo la ponderación de los canales sino incluso qué canales aparecen. Mientras que en los modelos extremos first-click y last-click solo teníamos 2 y 3 canales respectivamente, ahora aparecen todos. Es decir, todos los canales tienen aunque sea alguna influencia menor en las compras hechas.
Los modelos data-driven
Pensemos que estas diferencias ocurren con un ejemplo muy sencillo, con solo 4 conversiones. La variabilidad que pueden presentar estos modelos con datos reales es enorme. Y sin embargo, la atribución está en la base de las decisiones de inversión en marketing. Es decir, estos modelos van a decidir cómo orientar los recursos de un mercado que, como dijimos en la primera nota, es de 600.000 millones de dólares.
Viéndolo desde este punto de vista, tiene sentido que se hagan esfuerzos por comprender un poco mejor como interactúan los canales entre sí y que la decisión de a quién atribuir las conversiones de los canales digitales sea un poco más sofisticada. Por ese motivo se crean los modelos data-driven, es decir modelos que no están regidos por una regla definida de antemano sino que determinan a partir de los propios datos cuál es la proporción que le corresponde a cada canal de las conversiones totales del período.
A continuación vamos a ver los 2 modelos más utilizados hoy en día en la industria: uno basado en el cálculo del valor de Shapley y otro en modelos de compra como un proceso de Markov. “Shapley” (se dice “Sheipli” o “Shapli”, depende cuán cool te consideres) y “Markov” para los amigos.
Los supuestos de los modelos
Sin embargo, antes de meternos en los detalles de estos modelos, vamos a explicitar qué cosas estamos asumiendo. En contraste con los modelos MMM, los modelos MTA parten de considerar que lo que no medimos no tiene impacto en las ventas. Es decir, no vamos a tener en cuenta ni el gasto en canales offline (TV, radio, gráficas) ni los factores externos (economía, COVID, fechas especiales) porque nada de eso lo podemos analizar al nivel de cada usuario.
Obviamente este parece un supuesto muy fuerte (y lo es) pero tiene un sentido: los modelos MTA son modelos orientados a tomar decisiones de cartera en la inversión publicitaria (en qué canal pongo más plata) y esa decisión la vamos a tomar solo entre los canales digitales. Por ende, vamos a atribuir el 100% de las conversiones a los canales publicitarios digitales aunque sepamos que hay muchos otros factores que contribuyen a esas ventas pero que no están bajo nuestro control. Aunque sepamos que el 20% de las conversiones vienen por factores climáticos, no vamos a poder hacer nada para mejorar el clima.
Esto implica asumir, además, que los valores que va a arrojar este modelo de atribución son exagerados. Es decir, en el extremo si reducimos toda la publicidad digital a 0, el modelo nos va a decir que no hay conversiones o que no tienen explicación. Por ende, siempre el total de conversiones de cada canal va a estar sobreestimado. Sin embargo, lo que más nos interesa en los modelos MTA es la relación entre ellos (y entre sus costos) por lo cual nos interesa más la proporción de conversiones de cada canal que el valor absoluto que arroja el modelo.
Conclusiones
Con esta nota hicimos una pequeña introducción a los modelos MTA empezando por los heurísticos que son los definidos a partir de una regla arbitraria. Con este ejemplo pudimos ver cómo la atribución implica muchas decisiones y que los resultados pueden ser absolutamente diferentes según las definiciones que tomemos. Por eso se vuelve un problema tan relevante. También vimos qué supuestos estamos asumiendo al modelar de esta forma.
Una vez planteada esta introducción, pasemos ahora sí a inspeccionar en detalle los modelos MTA data-driven.
